|
I am a Ph.D. candidate at UESTC, advised by Prof. Jingkuan Song. My research aims to bridge the gap between virtual AI and the physical world by developing general-purpose robots, focusing on the creation of generalist policies that empower them to robustly perceive, dynamically interact, and continuously adapt—ultimately enabling them to tackle any task, in any environment. Email / CV / Google Scholar / Github |

|
|
|
|
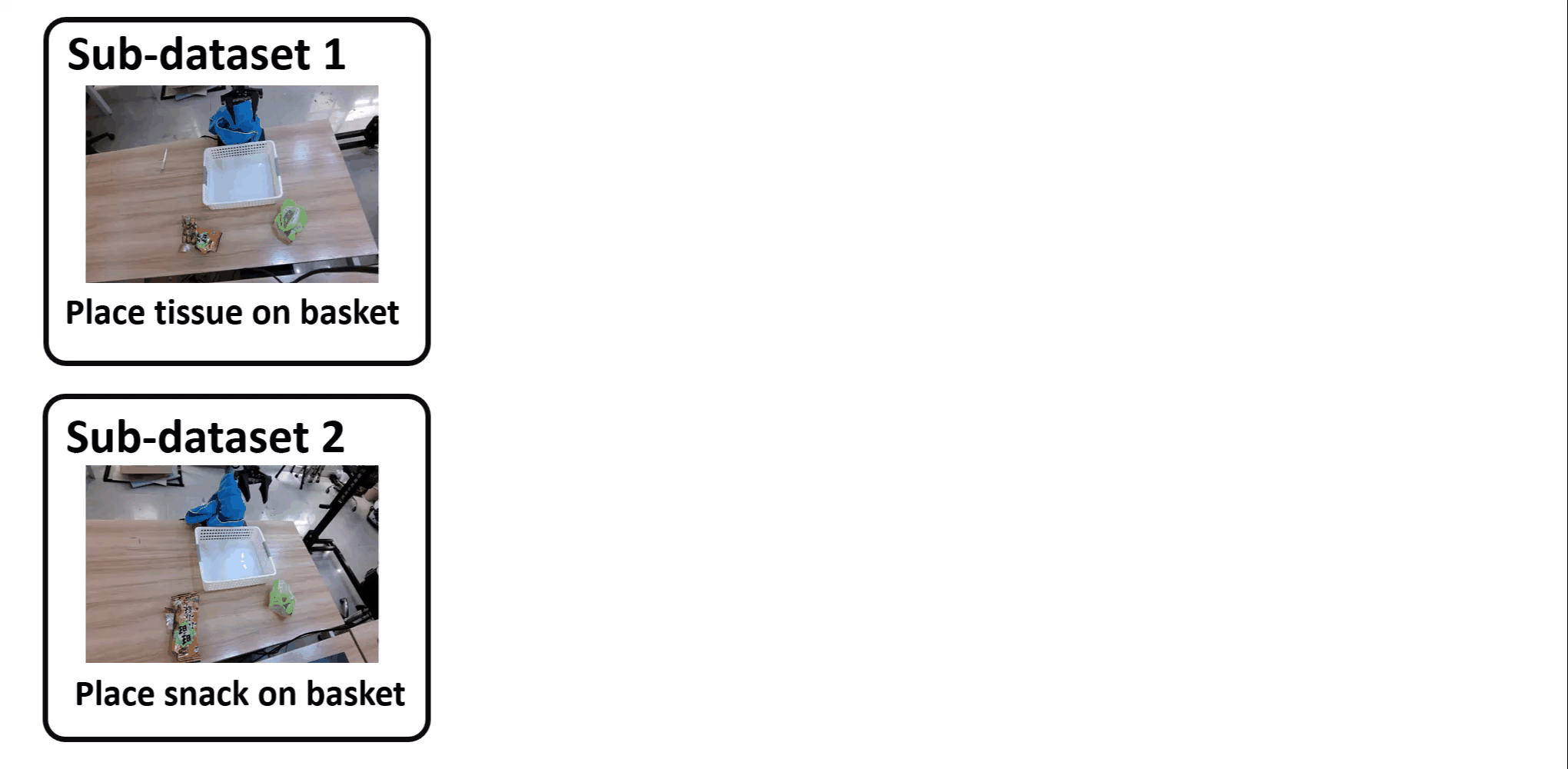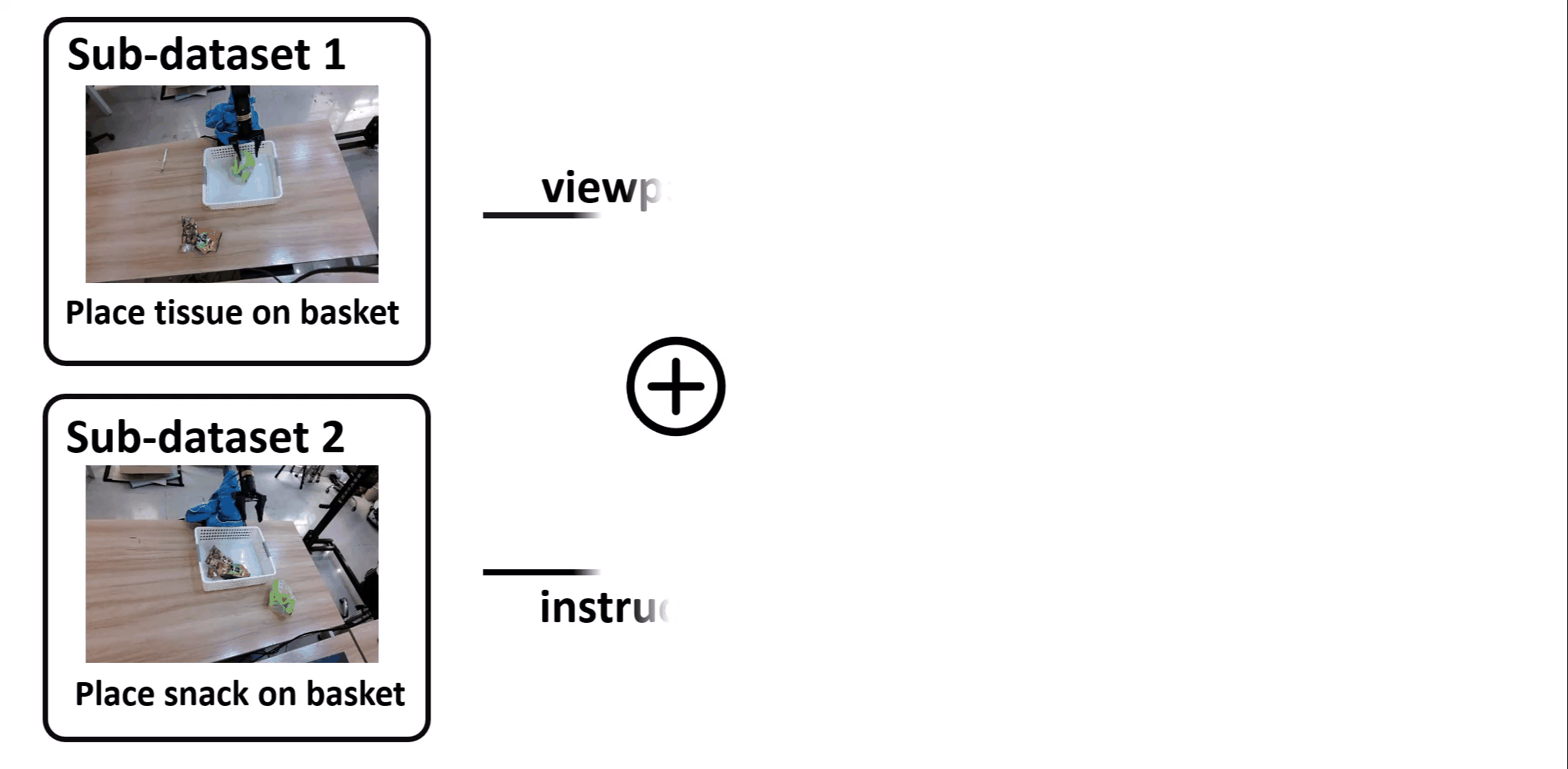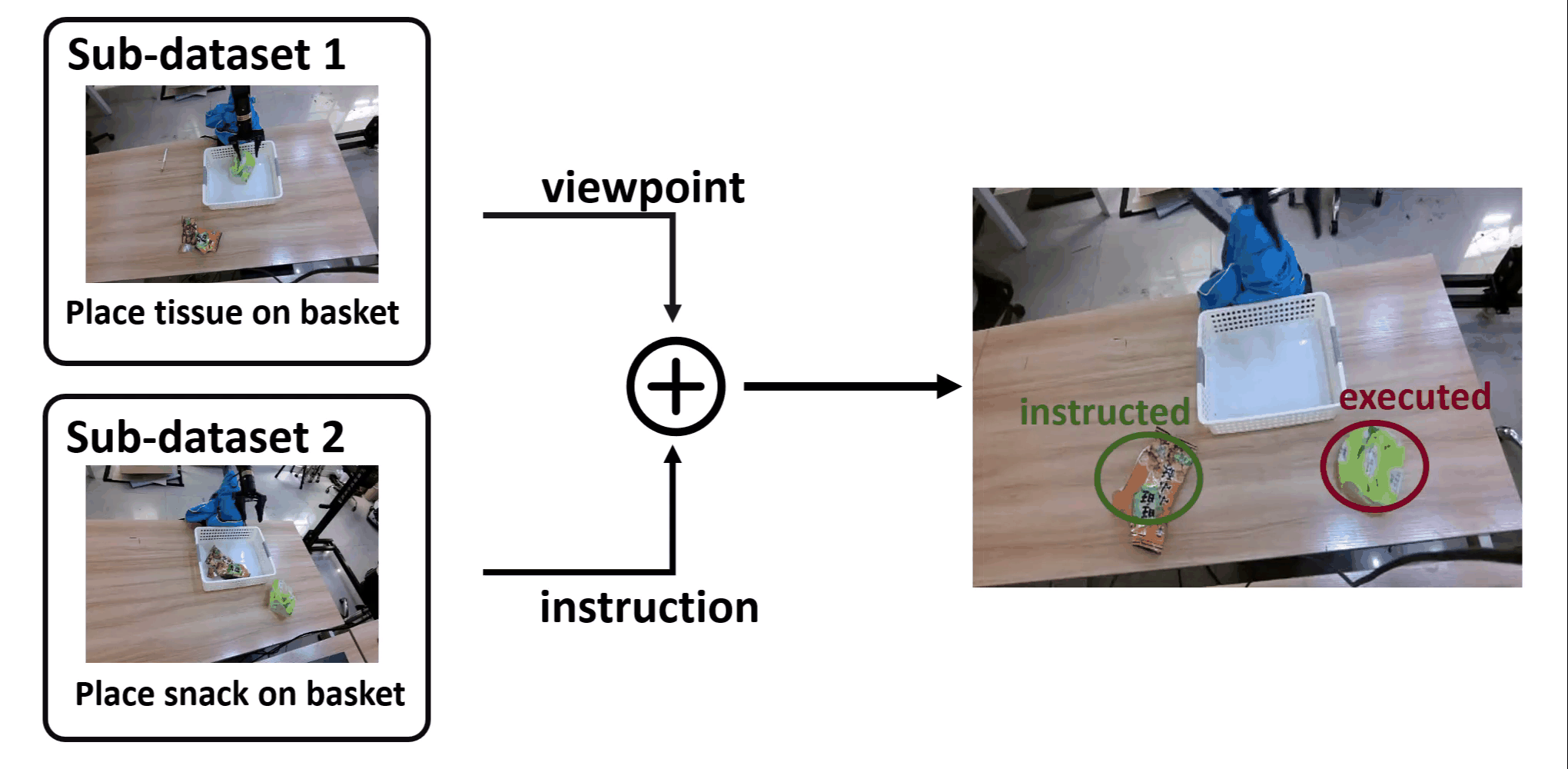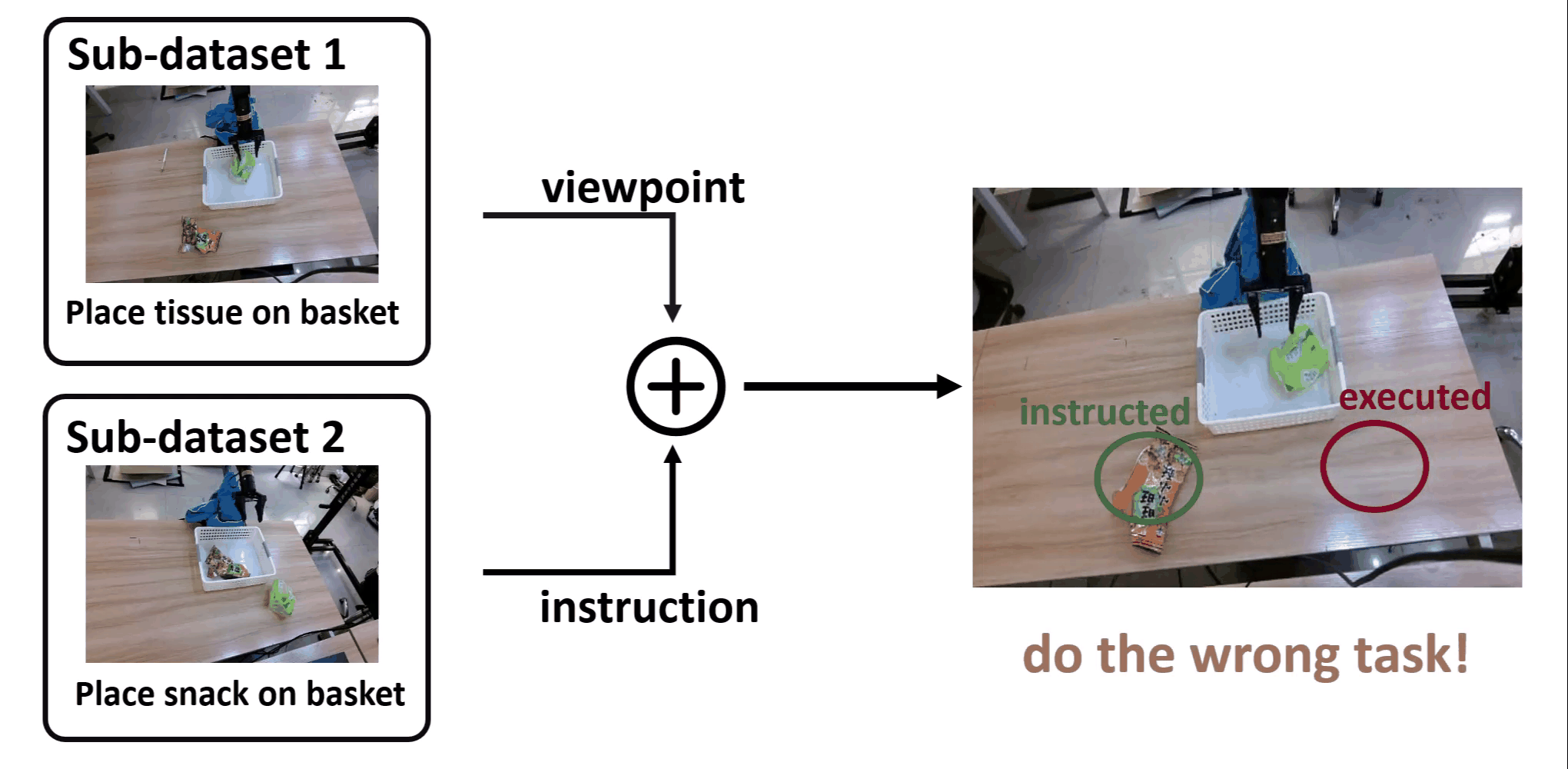
Youguang Xing*, Xu Luo*, Junlin Xie, Lianli Gao, Hengtao Shen, Jingkuan Song CoRL, 2025 [PDF] [Website] Identifying shortcut learning as a key impediment to the generalization of generalist robot policies and providing a comprehensive analysis. |

|
Xu Luo*, Hao Wu*, Ji Zhang, Lianli Gao, Jing Xu, Jingkuan Song ICML, 2023 [PDF] [Code] Empirically proving the disentanglement of training and adaptation algorithms in few-shot classification, and performing interesting analysis of each phase that leads to the discovery of several important observations. |
|
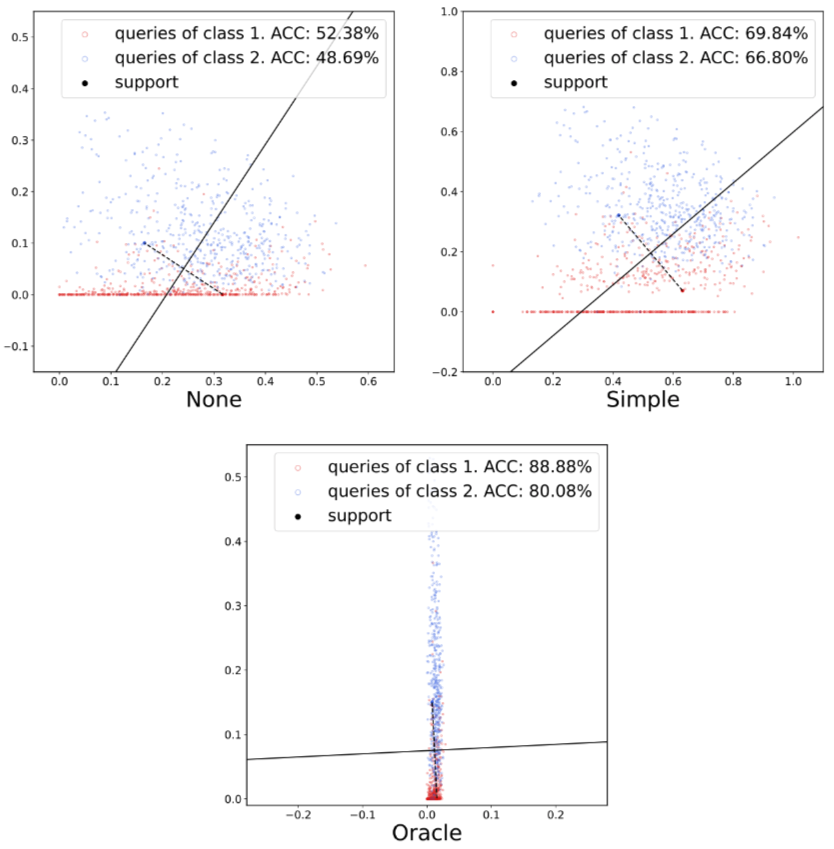
Xu Luo, Jing Xu, Zenglin Xu ICML, 2022 [PDF] [Code] Revealing and analyzing the channel bias problem that we found critical in few-shot learning, through a simple channel-wise feature transformation applied only at test time. |
|
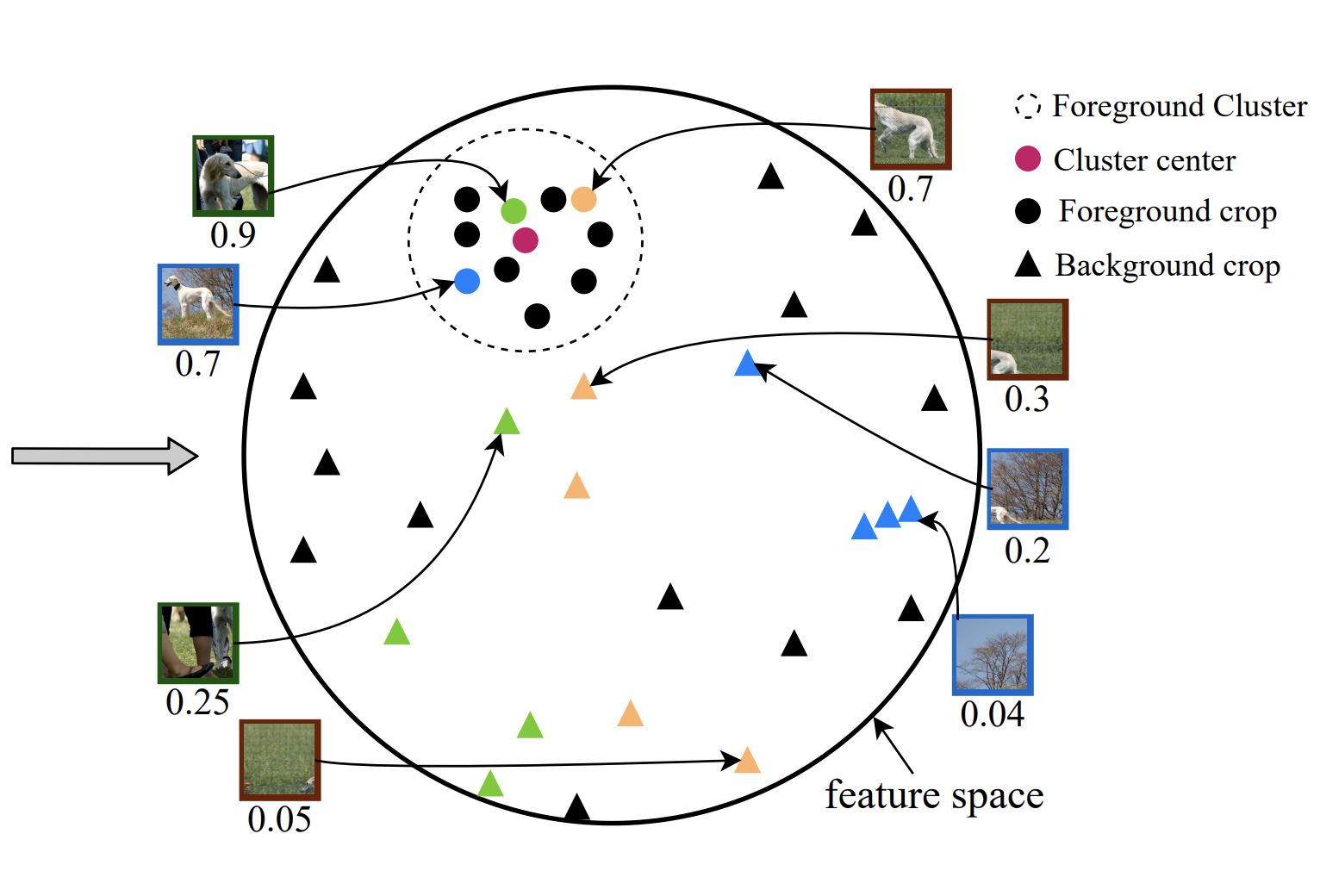
Xu Luo, Longhui Wei, Liangjian Wen, Jinrong Yang, Lingxi xie, Zenglin Xu, Qi Tian NeurIPS, 2021 [PDF] [Code] Identifying image background as a shortcut knowledge ungeneralizable beyond training categories in Few-Shot Learning. A novel framework, COSOC, is designed to tackle this problem. |
|
|
|
This well-designed template is borrowed from this guy |